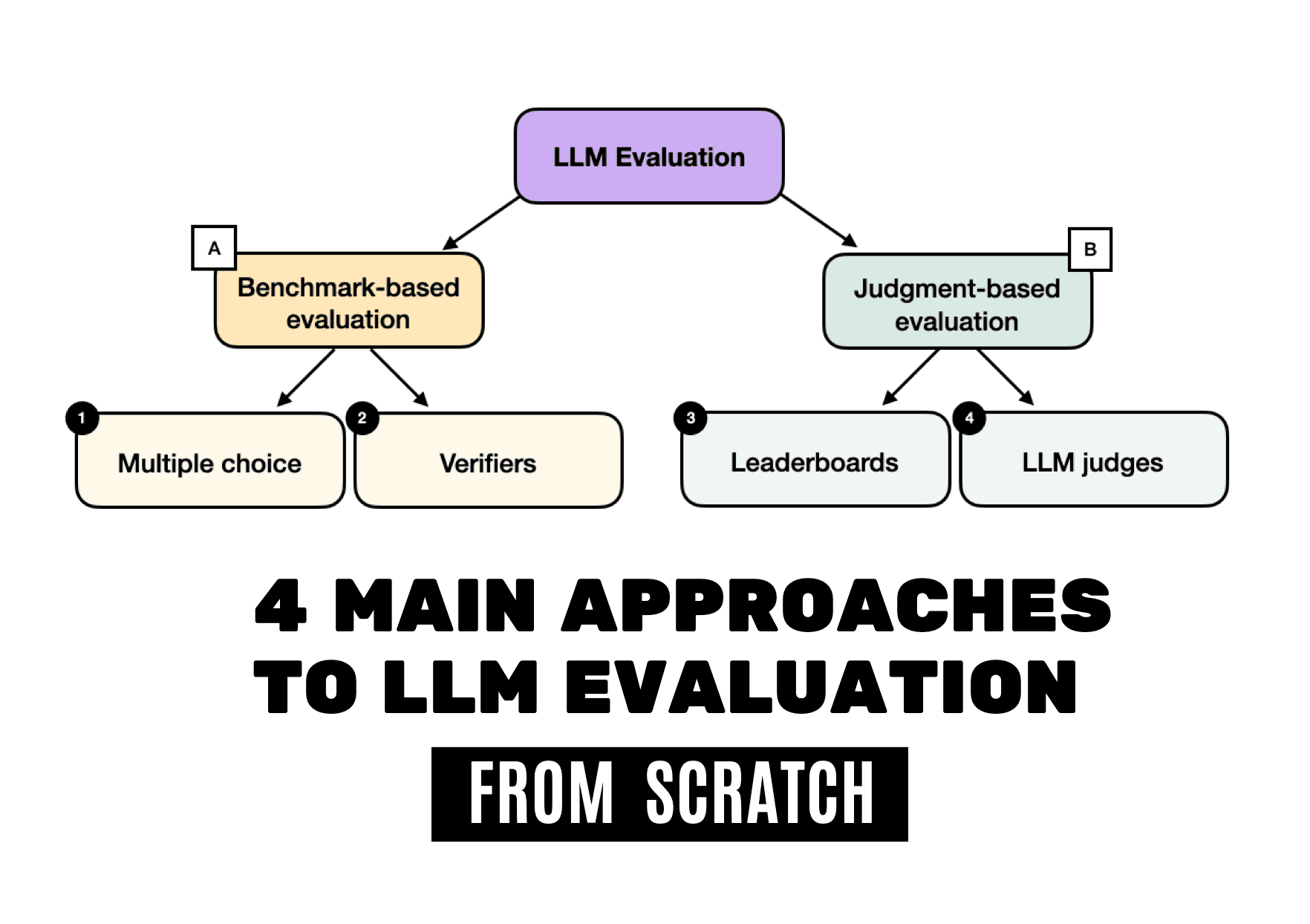
Most practitioners choosing between LLMs have no reliable framework for interpreting benchmarks, leaderboards, or fine-tuning results. This article by Sebastian Raschka fixes that. It maps the four main evaluation methods used in practice: multiple choice, verifiers, leaderboards, and LLM judges. Each method gets from-scratch code implementations in pure PyTorch, not abstractions, not wrappers.
The value here is not just the taxonomy. It is the side-by-side exposure of each method's failure modes. Leaderboards get gamed. LLM judges introduce self-preference bias. Multiple choice scores collapse under distribution shift. Verifier-based evaluation, the method Raschka uses most in his forthcoming book 'Build a Reasoning Model (From Scratch)', is the most rigorous but also the most constrained by task type. Understanding why each method breaks is more useful than knowing which number is highest.
This piece was originally scoped for Raschka's Manning early-access book, which already has over 100 pages live and focuses on verifier-based evaluation for reasoning models. The standalone article expands the scope to all four methods with runnable code. If you work on model selection, fine-tuning, or any pipeline where evaluation quality determines product quality, read the full piece before trusting another leaderboard score.
[READ ORIGINAL →]