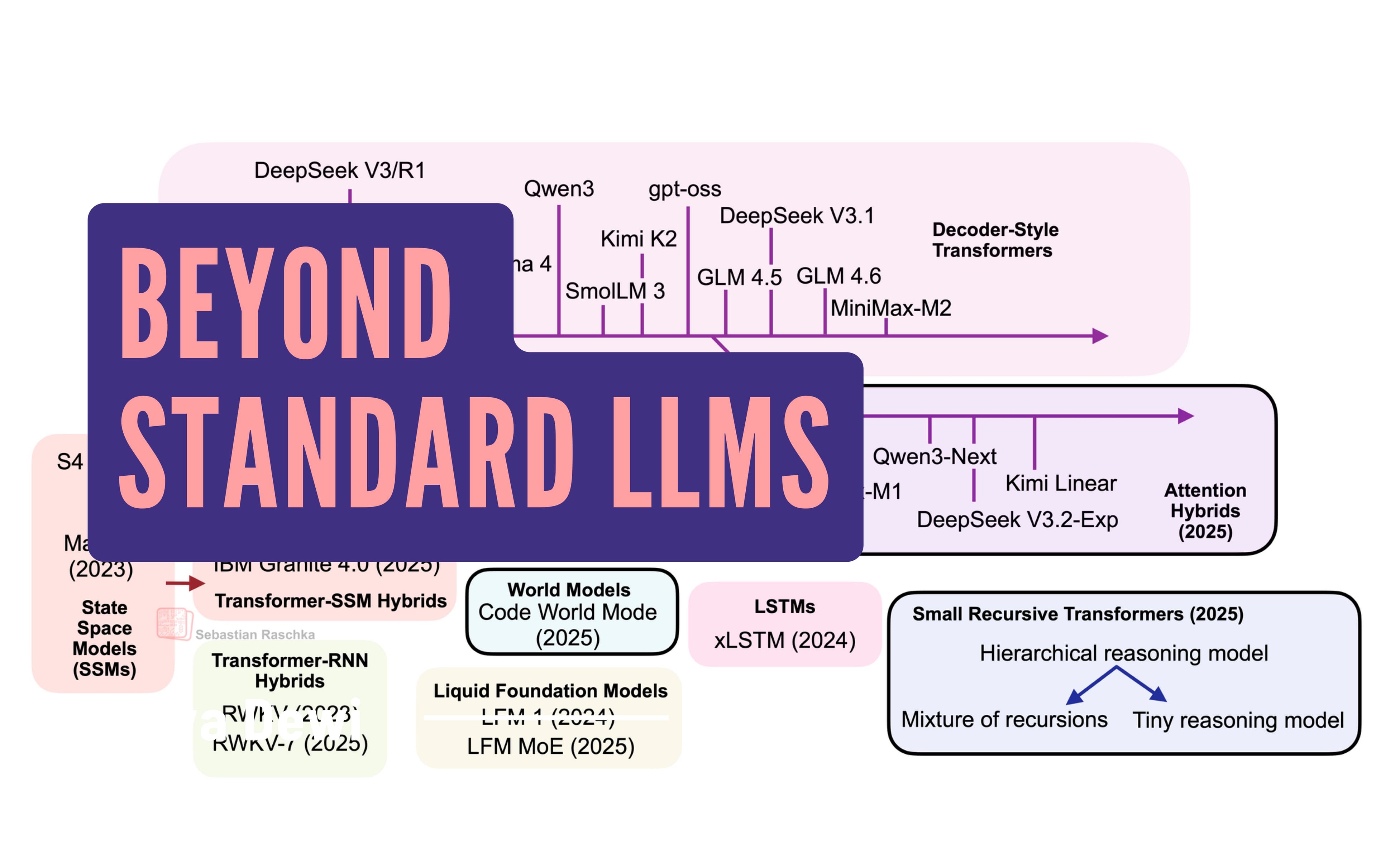
The dominant open-weight LLMs in 2025, from DeepSeek R1 to MiniMax-M2, are still autoregressive decoder-style transformers built on multi-head attention. That architecture, introduced in the 2017 paper 'Attention Is All You Need,' remains state of the art across text and code. But a serious field of alternatives has matured alongside it: text diffusion models, linear attention hybrids, and code world models, each targeting different failure modes of the standard approach.
This piece, a follow-up to a Big LLM Architecture Comparison and a talk at PyTorch Conference 2025, maps the full landscape of non-transformer architectures in one place. The value is not just the conclusions. It is the taxonomy: efficiency-motivated designs versus performance-motivated designs are separated, named, and explained with enough specificity to know which problems each one is actually solving.
The article is deliberately kept short per section because each architecture could fill its own dedicated piece. That constraint forces precision. If you work in model architecture, inference optimization, or just want to understand why the transformer might eventually cede ground in specific domains, this is the map you read before going deeper.
[READ ORIGINAL →]