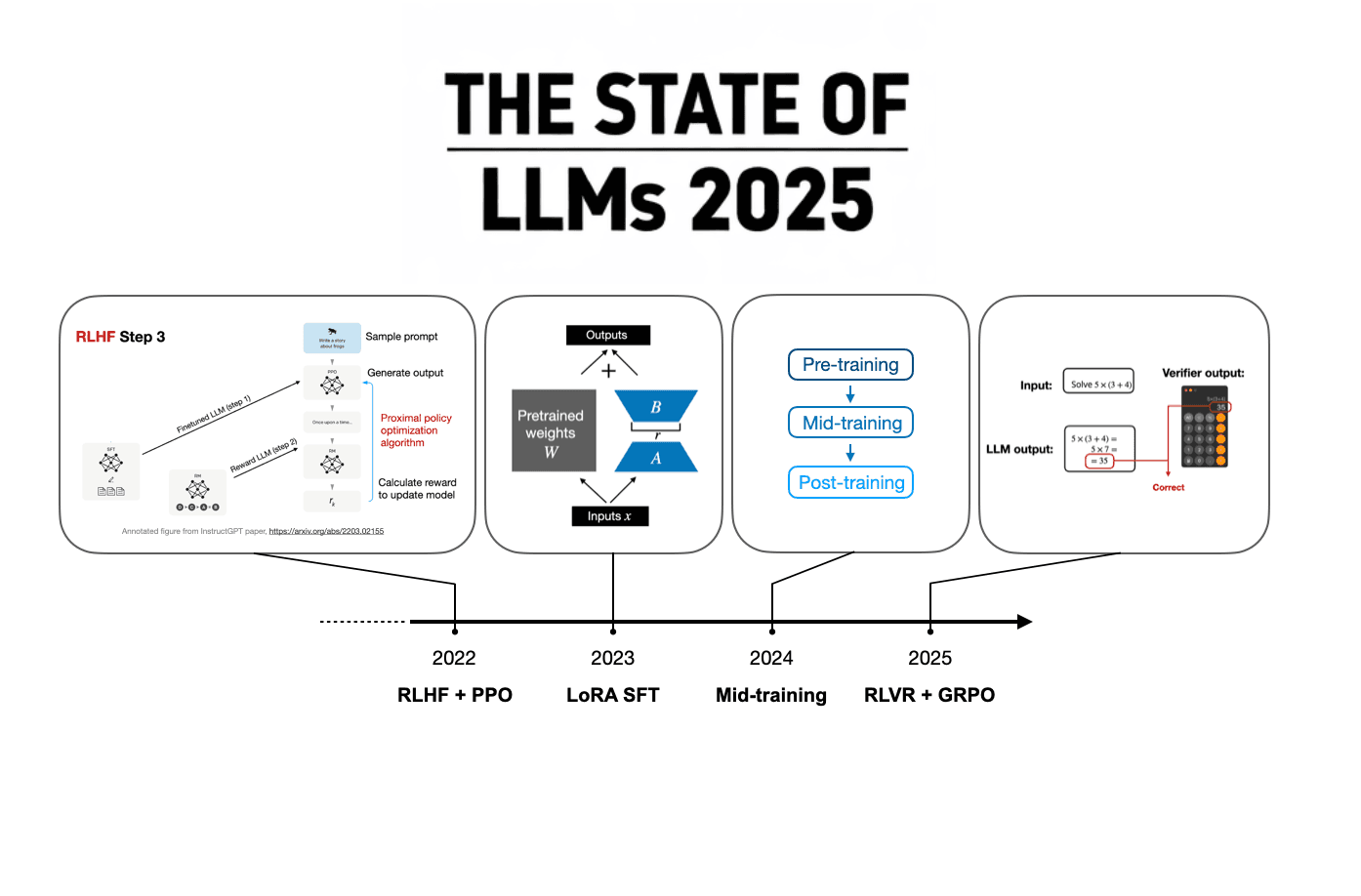
DeepSeek R1, released January 2025, was the year's defining technical event. The open-weight model matched proprietary competitors like ChatGPT and Gemini while its companion V3 paper revised frontier training cost estimates from hundreds of millions down to roughly 5 million dollars. The mechanism behind R1 mattered as much as the result: reinforcement learning via GRPO produced reasoning behavior, where models generate intermediate chain-of-thought steps that directly improve final answer accuracy. This was not a scaling story. It was a training methodology story.
The original article is worth reading in full because the author traces the technical lineage, not just the headlines. RLVR, the reinforcement learning from verifiable rewards framework underlying R1, gets a precise breakdown. So does GRPO, the specific policy optimization algorithm DeepSeek used instead of the more expensive PPO. These distinctions matter if you want to understand what is actually replicable and what labs are quietly building on top of it right now.
The broader 2025 picture the article builds toward is one where compute scaling has not stalled but is no longer the only lever. Reasoning via RL, cheaper training runs, and open-weight competitive models have changed the competitive surface. What comes next, according to the author, involves agent tasks, longer context utilization, and whether verifiable reward signals can extend beyond math and code into messier domains. The answer to that last question will define 2026.
[READ ORIGINAL →]