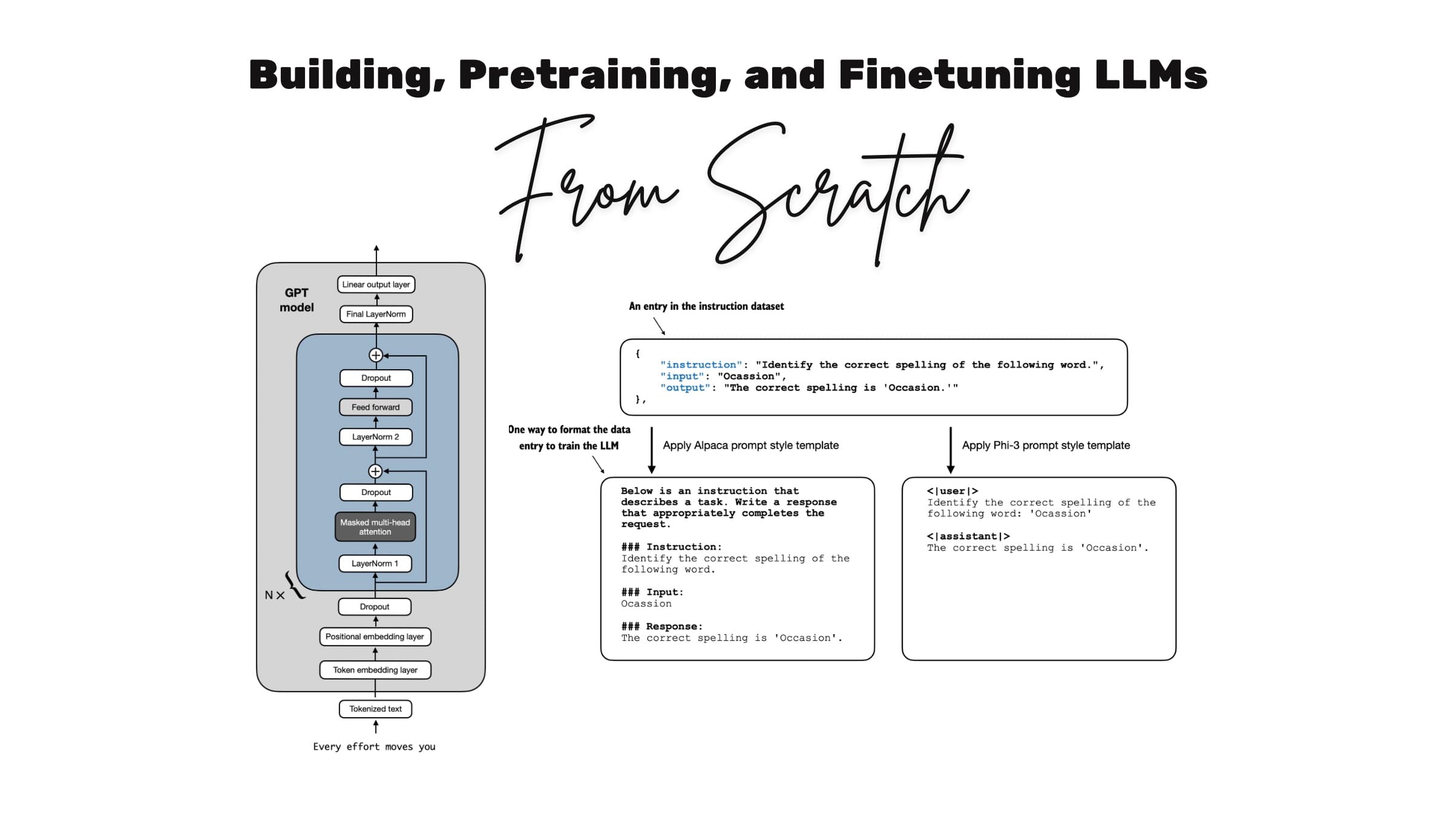
Sebastian Raschka, PhD, has released a 15-hour video course on building large language models from scratch in code. The series expands on his earlier 3-hour workshop, which drew 401 reactions and remains one of the most referenced pieces in his catalog. It originated as supplementary material for his book 'Build a Large Language Model From Scratch' but functions as a fully standalone curriculum.
The course covers the full implementation stack: Python environment setup with uv, text tokenization and byte pair encoding, attention mechanisms, and GPT-2 weight loading from both TensorFlow and a PyTorch-converted Hugging Face mirror at rasbt/gpt2-from-scratch-pytorch. Each video is a discrete, code-driven unit. The argument for this approach is precise: you do not learn how an engine works by reading the manual. You learn by assembling one.
Read the full piece for the complete video index, the GitHub repository at rasbt/LLMs-from-scratch, and the specific workarounds for Windows TensorFlow dependency failures. If you have spent time with high-level LLM APIs and want to understand what is actually running underneath them, this is the most direct path available in public, free form right now.
[READ ORIGINAL →]